Supervisor
Supervisor is where the main loop of Enchanted Surrogates is ran. Supervisor orchestrates use of samplers, executors and runners. See the chart below for overall structure of the code.
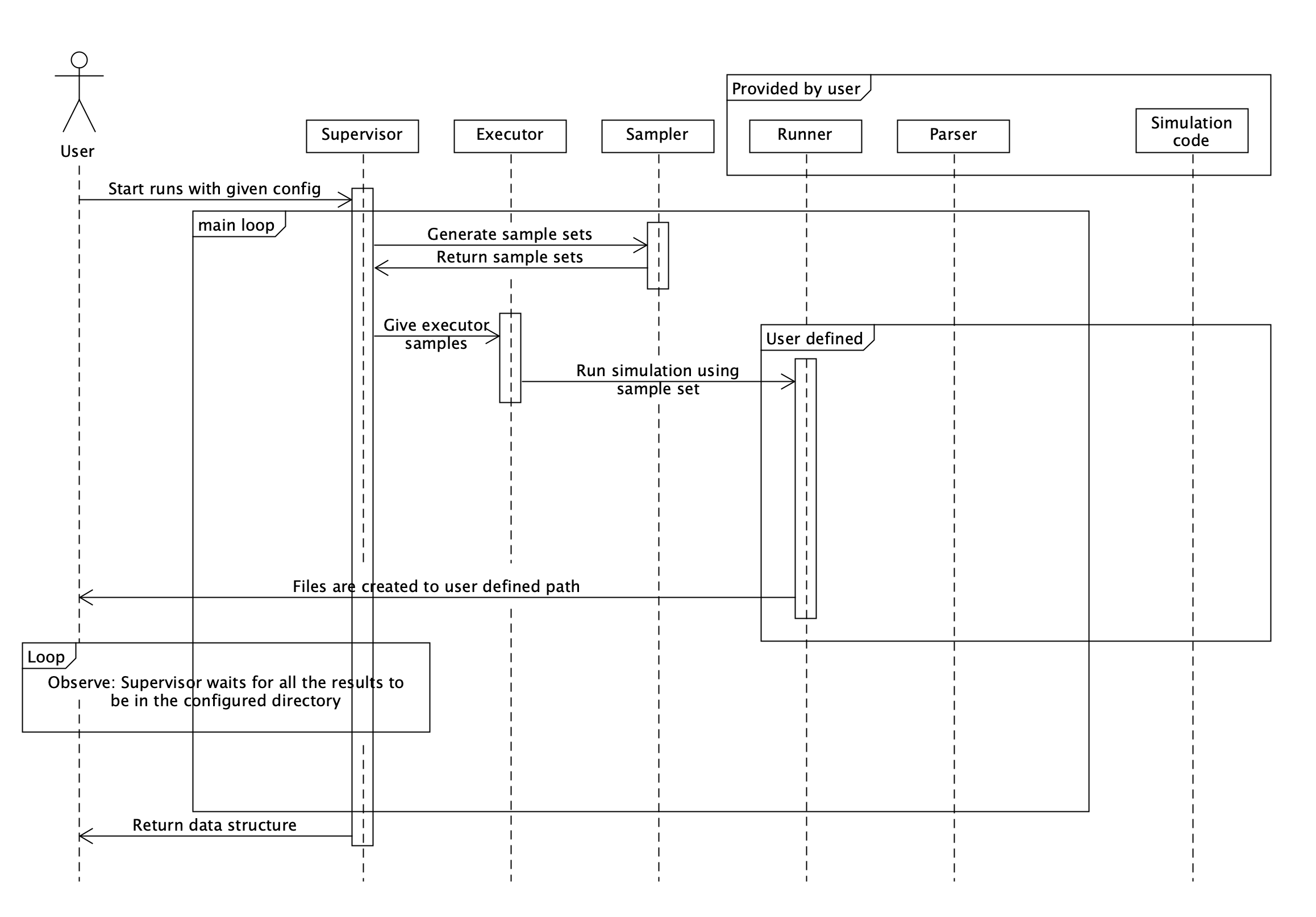
Configuration of supervisor
Supervisor needs base_run_dir defined in the configuration file. Example as
follows:
supervisor:
base_run_dir: "path/to/folder"
run_order:
- executor: ...
sampler: ...
runner: ...
Nested execution
Nested execution allows for running nested sampling schemes, which is useful when one code is used to generate input for another code.
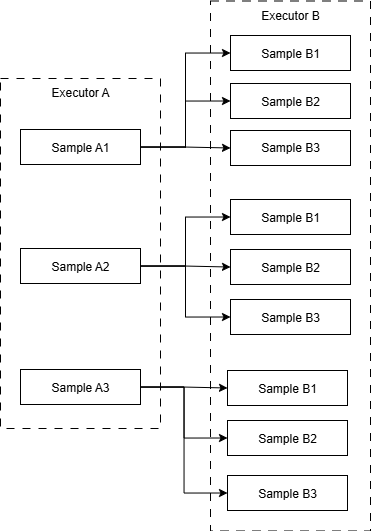
This type of workflow could be configured by
executors:
A: ...
B: ...
samplers:
SomeSampler: ...
runners:
RunnerA: ...
RunnerB: ...
supervisor:
base_run_dir: ...
run_order:
- executor: A
sampler: SomeSampler
runner: RunnerA
- executor: B
sampler: SomeSampler
runner: RunnerB
In this example configuration, the output of RunnerA can be used as input to
RunnerB. Executors, samplers and runners can be used multiple times in
different stages of the workflow, note that in this example, both runners use
SomeSampler.
See example_nested.yaml.
Multi-runner sequential execution
Alongside nested executing, the supervisor also supports sequential sampling. In sequential sampling, the sampler's batches are called once but the samples go through multiple runners which pass information to each other. This is useful for active learning use cases. Sequential sampling and nested sampling can be used together in the same configuration.
To utilize sequential sampling in configurations, multiple runners need to be defined in the config file as a list. The same applies to executors. The amount of executors and runners defined in run_order must be equal. If this is not met, an exception is thrown. Examples of sequential sampling are provided within the configs directory under example_sequential.yaml.
Example of how a run_order can be defined to perform sequential sampling:
supervisor:
base_run_dir: "data_dir/sequential_local"
run_order:
- sampler: code1_sampler
executor:
- code1_executor
- code2_executor
- code3_executor
runner:
- code1_runner
- code2_runner
- code3_runner
Resuming/extending previous runs
The supervisor supports seamlessly resuming a previous run, in case of crashes
or timeouts. The previous run can also be extended with more sample points if
desired. This is configured with the run_mode config option.
supervisor:
base_run_dir: ...
run_mode: "fresh" # "resume" / "extend"
run_order:
- executor: ...
sampler: ...
runner: ...
"fresh"
Normal run and the default
"resume"
- Resume an interrupted previous run:
- Set
run_mode: resumeunderSupervisorin the config file, no other changes are needed. -
Supervisor keeps track of the run state (how many batches sampled, which nesting depth, and how many samples have been submitted) and using this data restores the run from where it left off and continues from there.
-
Resume a previous run that was completed but increase the budget:
- Set run mode to resume and also increase the budget of the sampler. From Supervisor point of view, this is same as if the budget always was that much and the run was just interrupted.
- Eg. increasing budget from 50 to 60 and re-running generates 10 new samples.
"extend"
- Extend a previous run:
- Set
run_mode: extendunderSupervisorin the config file - Now setting sampler budget to 10 means that 10 new samples are created.
HPC cluster local storage
Some partitions on some HPC clusters have access to local memory on the run
node. Setting the local_storage environment variable appropriately could
potentially improve I/O operation performance.
supervisor:
local_storage: TMPDIR
CSC users, see for example https://docs.csc.fi/computing/disk/#temporary-local-disk-areas
Optional attributes
Also, it is possible to define that enchanted_dataset summary file combining all run results is parquet instead of csv. CSV is default and does not require any configuration.
supervisor:
summary_datatype: "parquet" # csv by default
Configuring output files
Enchanted surrogates creates lots of intermediate files and by default, all are
retained after execution. Keeping or automatically deleting these files can be
configured by save_files and save_files_list supervisor config options:
supervisor:
base_run_dir: ...
save_files: "all" # or "custom" or "none"
# if using custom, only the specified files are saved
save_files_list:
- enchanted_dataset.csv
- example_local.csv
- ...
Hdf5 storage file is not saved if type for it is None. It is created in every other case.
storage:
type: "hdf5" # or "None"
It is possible to delete unnecessary files from base_run_dir and keep only wanted files. By default all is saved. Option custom saves only described files. None does not save any files.
Note: enchanted_dataset.csv, runs.h5 and logs are always saved.
supervisor:
save_files: "all" # or "custom" or "none"
# if using custom, only described files are saved
save_files_list:
- file.txt
- file2.txt
See config folder for example configurations.
Module supervisor.supervisor
Supervisor module.
Provides the Supervisor class, which coordinates configuration, execution, sampling, and result aggregation for simulation runs.
Supervisor
Supervisor(args, config_path=None)
Creates supervisor which handles configuration, running and file output of the program.
Attributes:
| Name | Type | Description |
|---|---|---|
args |
Namespace
|
Namespace containing the configuration parameters |
Initializes supervisor and sets class attributes.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
args
|
Namespace
|
Namespace containing the configuration parameters. |
required |
config_path
|
str or None
|
Optional path for configuration file where configuration is fetched from. |
None
|
Source code in src/enchanted_surrogates/supervisor/supervisor.py
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 | |
all_processes_done
all_processes_done(name_filter=None)
Monitors simulation processes and returns boolean describing state. Helper function for wait_all_processes.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
filter
|
str or None
|
Optional filter used to limit checking to run directories containing this text. If None (default), all run directories are checked. |
required |
Returns: True when all simulations are done. Helper function for wait_all_processes. Checks inside base_run_dir if folders inside it contain "enchanted_datapoint.csv" files. False If any runner has not yet created the csv file
Source code in src/enchanted_surrogates/supervisor/supervisor.py
422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 | |
batch_dirs_done
batch_dirs_done(run_dirs)
Checks if enchanted_datapoint.csv files exist in the directories list given
Attributes:
| Name | Type | Description |
|---|---|---|
run_dirs |
list[str]
|
List of running directories within the batch |
Return
False if any of the datapoint files in the run_dirs is missing True if all datapoint files are found
Source code in src/enchanted_surrogates/supervisor/supervisor.py
488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 | |
continue_with_base_run_dir
continue_with_base_run_dir(config_path)
Deletes old unfinished bathes prompting the user if they want to keep them Creates a base_run_dir if one does not exist
Attributes:
| Name | Type | Description |
|---|---|---|
config_path |
str or None
|
Optional path for configuration file where configuration is fetched from |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 | |
create_base_run_dir
create_base_run_dir(base_run_dir, config_path)
Creates base directory for simulation run results. Checks if base_run_dir is empty. Prompts user option to delete existing data in base_run_dir. Execution is stopped if user chooses to not delete files. Copies config_file to base_run_dir if config_file was provided.
Attributes:
| Name | Type | Description |
|---|---|---|
base_run_dir |
str
|
Path where runner saves result files |
config_path |
str or None
|
Optional path for configuration file where configuration is fetched from. |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 | |
create_dataset
create_dataset()
Creates pandas DataFrame that includes all the "enchanted_datapoints.csv" files of running directories inside base_run_dir.
Return
pandas.DataFrame containing all the enchanted_datapoint.csv files created by runners.
Source code in src/enchanted_surrogates/supervisor/supervisor.py
465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 | |
delete_unwanted_files
delete_unwanted_files(
argument, base_dir=None, extra_keep_files=[]
)
Deletes files according to command given.
Source code in src/enchanted_surrogates/supervisor/supervisor.py
722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 | |
fetch_from_local_storage
fetch_from_local_storage()
Moves all files from local_storage to base_run_dir, if local_storage is defined.
Source code in src/enchanted_surrogates/supervisor/supervisor.py
762 763 764 765 766 767 768 769 770 771 | |
finalize_summary
finalize_summary(filename='enchanted_dataset')
Finalizes summary after all the batches have been processed. Currently creates parquet summary file if configured in the configuration file.
Attributes:
| Name | Type | Description |
|---|---|---|
filename |
str
|
base filename without extension for summarized file |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 | |
get_cartesian_product
get_cartesian_product(samples, last_dataset)
Creates cartesian product of the new samples and the previous dataset. Used for nested sampling.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
samples
|
list[dict]
|
Sample batch from get_next_samples |
required |
last_dataset
|
DataFrame
|
The complete dataset (summary file) from previous nesting level. |
required |
Returns:
| Name | Type | Description |
|---|---|---|
out |
list[dict]
|
Cartesian product samples x last_dataset. If last_dataset is empty, only the unaltered samples are returned. |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 | |
hdf5_append_datapoints
hdf5_append_datapoints(new_dirs)
Appends new datapoints to the hdf5 storage file. This allows removing the intermediate files and directories after each batch run.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
new_dirs
|
list[str]
|
List of new datapoint directories created during a single batch |
required |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 | |
hdf5_write_aggregate_dataset_and_metadata
hdf5_write_aggregate_dataset_and_metadata(
enchanted_dataset,
)
Writes the completed dataset and run metadata to the hdf5 storage file. Dataset has only numeric values, column headers are saved separately in the same location. Metadata includes types for sampler, executor and runner.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
enchanted_dataset
|
DataFrame
|
Dataframe containing all run results |
required |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 | |
load_batch_to_df
load_batch_to_df(run_dirs)
Creates pd.DataFrame combining enchanted_datapoint.csv files in given path list folders
Attributes:
| Name | Type | Description |
|---|---|---|
run_dirs |
list[str]
|
List of running directories within the batch |
Returns:
| Type | Description |
|---|---|
DataFrame
|
pd.DataFrame containing batch datapoints combined |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 | |
read_summary
read_summary(filename='enchanted_dataset')
Reads the summary written by write_summary.
Attributes:
| Name | Type | Description |
|---|---|---|
filename |
str
|
base filename without extension for the file to be read |
Returns:
| Type | Description |
|---|---|
DataFrame
|
pd.Dataframe: dataset from the disk or an empty DataFrame if not found |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 | |
start
start()
Main function of the supervisor. Starts the simulation process. Currently is the only function, that is accessed outside of supervisor.py. Gathers samples and paths, and gives them to executor. After all processes are finished, creates summary file.
Source code in src/enchanted_surrogates/supervisor/supervisor.py
110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 | |
wait_all_processes
wait_all_processes(name_filter=None)
Waits in while loop until all simulations are done. Loop is broken when all_processes_done returns true. Checks condition once in second.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
filter
|
str or None
|
Optional filter used to limit waiting to run directories containing this text. If None (default), all run directories are waited. |
required |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 | |
write_summary
write_summary(
dataset, filename="enchanted_dataset", write_mode="a"
)
Writes a summary of dataset to base_run_dir/filename This functionality is used within the start function to enable seamless sampling. It appends each dataset on top of the previous dataset by default.
Attributes:
| Name | Type | Description |
|---|---|---|
dataset |
DataFrame
|
batch to be written |
filename |
str
|
base filename without extension for the written file |
write_mode |
str
|
style of writing summary. appending ("a") is default, write ("w") is used for overwriting summary |
Source code in src/enchanted_surrogates/supervisor/supervisor.py
247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 | |